

A.I. Needs Design Thinking (Part 2 of 2)
A.I. Needs Design Thinking (Part 2 of 2)
A two-step framework for applying design thinking to A.I.

In Part 1, I discussed the peculiar gap in how A.I. products deliver on their promise, ranging from products that result in abuse and outrage, to products that work so well they feel magical.
In this post I will share a two-step framework to apply design thinking to A.I. products in order to bridge that gap. Design thinking imposes a user-centric approach that leads to better product experiences. In the case of A.I. though, it also helps us reduce execution risk and development cost.
Step 1: To Succeed, Design Failure Away
The first thing to consider when solving an A.I. problem is what happens when it fails. The impact of failure can range from inconvenient, to life threatening. So it’s important to have a clear understanding of the two types of A.I. failure, and also understand their frequency and impact in your application. This would help you make whatever improvements necessary, to product definition and user experience, in order to mitigate or reduce the impact of those failures.
To start, first let’s review the two primary ways an A.I. can fail. Assume we are developing a product to diagnose some disease. The A.I. can fail by generating false positives (when it mistakenly flags a healthy patient as sick), or false negatives (when it fails to flag a sick patient). By measuring these two errors, we can characterize the accuracy of the A.I. using a few statistical measures, two of which are worth mentioning here:
Precision: When the model flags a patient, how often is it correct? A model with 90% precision is right 90 out of every 100 times it flags a patient as sick. Another word, fewer false positives lead to higher precision.

Sensitivity (a.k.a., recall): When looking at sick patients, how often do we correctly identify them as sick? A model with 90% sensitivity flags 90 out of 100 sick patients. To improve sensitivity, we often focus on decreasing false negatives.
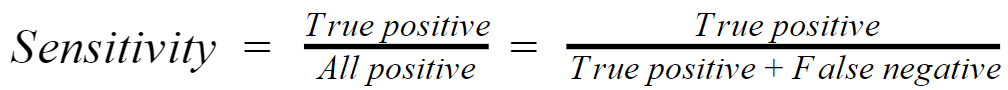
To better understand the contrast, a model that's 100% sensitive but 50% precise can identify all sick patients, but for every sick patient it also mistakenly flags one healthy patient. On the other hand, a model that's 50% sensitive but 100% precise can only identify half of the sick patients, but whenever it flags someone as sick, they certainly are.
False positives and false negatives have critical implications on A.I. products because it's the impact of these failures that define our success or demise. Say, our disease diagnostic model has 90% sensitivity (i.e., missing 10% of sick patients), and 90% precision (i.e., 1 out 10 flagged patients are not actually sick). Is this a good model?
It depends! Let’s consider the context. Say we’re testing 1,000 patients a week, and on average 200 are sick. This means our model will miss 20 sick patients per week, and will also erroneously flag 20 healthy patients as sick. Is this a good model?
Still, it depends! What do we actually do with these results? If we automatically dismiss every negative patient, we will put 20 lives at risk every single week by failing to provide timely care. But if our results are only used as an input to human review—as in, if another set of eyes looks at the patient files before further action is taken—then our current model performance may be satisfactory. For example, it is reported that doctors miss 1 in 5 cases of breast cancer in mammograms. If we can successfully flag 90% of cancerous images prior to a doctor review, it could result in a more careful examination of many cases that currently go unnoticed.
So whether an A.I. is suitable to a problem depends heavily on how it is used. Understanding the cost of failure leads us to adjust the levers we have, such as user experience design, product definition, or even go-to-market strategy, to set ourselves up for success. Real-time facial recognition of pedestrians may result in costly failures, but the same tool used on detainees works fine. A standalone disease diagnostics product could risk lives, but one that augments doctors workflow would save lives.
Step 2: Create and Harness Asymmetric Accuracy
By designing away the costliest A.I. failures, and by increasing tolerance for the remaining errors, we also get to simplify the model that needs to be built. Creating good A.I. models require investment of time and resources, including the usually expensive process of collecting and labeling large volumes of training data. When we require very low false positive and false negative rates, we effectively need a more complex model that could take considerably more time to develop and more data to train.
Designing with A.I. complexity in mind can lead to success of not just your product but your startup or business unit. So it may be worth quantifying complexity and taking a closer look at how we can simplify. While complexity is too hard to measure, I find another statistical measure, the F1 score, quite useful as a rough estimate that provides a sense for how hard of an A.I. problem we’re dealing with.
In essence, F1 is a single metric that combines both precision and sensitivity in order to represent an overall accuracy measure. The score ranges from 0 to 100%, with a score of 100% representing a perfect algorithm with no false positives or negatives whatsoever.

If we plug in our product requirements for sensitivity and precision (or for false positives and negatives) into the F1 equation, we can get a sense of how complex of an A.I. we are going to need. That in turn gives us a sense for the development cost and time to market. Arguably, an F1 score of 100% represents the most complex model in its problem space, so our goal must be to decrease this complexity score by lowering our accuracy requirements.
Note how the F1 score highlights an interesting opportunity to harness asymmetry in accuracy requirements. The chart below is a visual representation of this effect. Greener cells highlight less complex scenarios, and red is more complex. As you can see, it’s possible to increase one axis and still stay out of red zones—as long as the other axis is kept low. A problem that requires high sensitivity but can tolerate low precision (or vice versa) could be solved cheaply and easily. Problems get harder and more complex only when we need both high sensitivity and high precision. And my experience shows that how we design products can often determine whether we need both performances to be high, or only one.

Let’s look at this numerically. The least complex model in the chart above is when sensitivity and precision are both at 50%—F1 is 50% too. On the other hand, if both are at 99.9%, the F1 shoots up to 99.9% as well. Effectively this means that our tolerance for error is reduced by two orders of magnitude. Not surprisingly, this would require the development of a more complex A.I.
However, now imagine if we had to increase sensitivity to 99.9% but could afford to keep precision at 50%. That increases F1 from 50% to 67%, which is significantly lower than an F1 of 99.9%. By increasing sensitivity to 99.9% we have reduced our false negative rate by more than two orders of magnitude (i.e., 500x reduction), yet our complexity score only increased by a rather marginal amount (~1.4x).
We can apply this to our disease diagnostics product. Remember that our A.I. had a 90% sensitivity and 90% precision—thus an F1 of 90%. Given our 1,000 weekly patients (200 being sick), our model will miss ~1,000 sick patients annually, and also result in ~1,000 patients falsely identified as sick.
This is a great opportunity to harness asymmetric accuracy, because the true cost of false negatives and false positives are considerably different. A false negative is an undetected sick patient whose life is at risk, but a false positive is someone’s inconvenience in having to do another test. If we were to reduce our false negatives to 1/100th of what they currently are (two orders of magnitude decrease) while accepting some increase in our false positives (say 2x), that leads to a sensitivity of 99.9% and a precision of 80%. That means we’ll miss only 10 sick patients a year, not 1,000, but we’ll need 2,000 patients to get re-tested. Having 990 more lives saved at the cost of an additional 1,000 re-tests sounds like a very desirable outcome!
The result is that our F1 score is now at 89%, which is in fact slightly lower than the 90% we started with. As a rough indicator of complexity, this goes to show that we can achieve considerably more desirable outcomes without having to increase the engineering time and effort. In fact, we may not need to do any additional development at all. Balancing between precision and sensitivity can often be done by tuning model parameters. But doing so requires that our product, design, and A.I. leaders understand the levers they have at hand, and that they also understand how those levers impact users.
The difference we can make by harnessing such asymmetry can be the difference between a successful product and a failed one. Knowing the power of asymmetric accuracy, we must design products that include more asymmetries. Most content personalization products (e.g., news feeds, music, videos) leverage this. Their users are highly sensitive to false positives (a content presented that they dislike), but are completely indifferent to false negatives (a desirable content that was never presented). Users only see what's presented, not what was never shown! To some degree, the same is true with Google Photos. Users notice the faces it magically detects in 50-year-old photos, but don’t think twice if it fails to detect some other faces. All we have to do is tune the models against false positives (thus a high precision) because we want every identification to be correct. We can do this at the cost of more false negatives (low sensitivity) because users don’t mind if occasionally some people aren’t identified.
Going back to our first question, this type of product design is what explains the gap between my scale and my photo library. One product is designed around its A.I., successfully hiding failures away, whereas the other lets every failure become a user friction.
The Silver Bullet Fallacy
Let me conclude by sharing a personal story. In 2013, I was leading the engineering team at a small, bootstrapped startup. We were developing a smart home product that helped people save energy. It worked by showing users how much energy each appliance consumes (e.g., heater, fridge, T.V., etc.). This was done via a sensor mounted inside the home's electrical panel that measured the total energy usage of the home, every second. We then used A.I. to observe the fluctuations in energy usage and look for the fingerprints of various household appliances to measure their energy use.
Our most direct competitor was a Bay Area startup backed by a top tier VC. They too used A.I., first to identify what appliances are in the home, and then to estimate their energy usage. On paper, that made sense. But in reality, maybe not. When one of our executives installed their product in his house, he received an email informing him that his pool pump was costing $100 to run each month. Except, he didn’t have a pool!
We took a different approach. During onboarding, we simply asked users to select their major appliances from a list. This simple design decision had important implications:
First, it hid our false positives from users! We’d never show a user an appliance they don’t have.
Second, it made our models more accurate. Having a true list of user’s appliances meant that we did not need to match fingerprints against all appliances in the world. We just had to look at a small subset of appliances the user had already told us they have. In computer science terms, this transformed our problem from a global search (more complex) to a local search.
Finally, the introduction of our product coincided with heightened privacy concerns about smart devices. While an algorithm that can figure out what appliances you have at home without your input may seem very impressive—a fun problem to solve if you’re an engineer—to users that just seemed creepy! Our decision to simply ask users to list their appliances had the advantage of not making them feel tracked or violated when the results of our algorithm was presented.
I believe the opportunity for design thinking to simplify A.I. is not an accident of nature. It is because the hype surrounding A.I. is leading many to a common pattern of unnecessarily adding complexity to products. The complexity stems from hyped expectations—often by makers, not users. Many innovators, founders, product managers and engineers who are trying to apply A.I. to their problems fall for the "silver-bullet fallacy": treating A.I. as a magical tool that can solve just about anything. This leads to over-engineering, to solving fun and sexy problems rather than focusing on the simplest way to solve actual user problems.
Hypes have a tendency to lead us to congregate around them. That means we put the subject of the hype at the center of our attention. The antidote to this inadvertent complexification is design thinking. It is when we put the users at the center of our efforts, not the A.I. As technology leaders, we have a unique opportunity to break this anti-pattern and make products that are simpler and more elegant. In turn, we get to meaningfully impact our businesses by reducing execution risk, development cost, and time to market.
If you found this series useful, subscribe here for future posts.